
Just last week, the launch of DeepSeek R1 has taken the AI world by storm. It surpasses industry-leading models in performance at a fraction of the cost, and even more remarkable, it's open-source to the research community! This breakthrough is being hailed as a "Sputnik moment" in the AI industry.

The researchers at DeepSeek also released a great research paper on the R1 model:
In this note, I’m going to give a try on explaining the paper and discussing its key concepts in simple terms!
Chain of Thought
Chain of Thought is a simple yet effective technique in prompt engineering. It involves asking the model to articulate its thought process step-by-step. By incorporating this technique into our prompts, we essentially request the model to provide a detailed explanation of its reasoning.
Here's an example from the research paper illustrating the thought process of the model when presented with a mathematical question. You can see that the model engages in reasoning and provides step-by-step explanations of its solution. If the model made any errors, we can easily identify the reasoning error and instruct the model to not make the mistake again.

During the training process of DeepSeek R1, a phenomenon known as the "aha moment" occurs. During this phase, the model spends more time to re-evaluate its initial approach. As a result, the model can provide significantly more accurate responses compared to when it simply provides a response without any reasoning.

Reinforcement Learning
Reinforcement Learning Overview
DeepSeek R1 utilizes a unique approach to Reinforcement Learning compared to most other AI models. Unlike most other models that are trained by feeding them with a bunch of questions and corresponding answers, known as "supervised data," DeepSeek R1 just learns on its own without relying on these data sets.
This is similar to how a baby learns to walk for the first time. Initially, the baby stumbles and relies on objects to support their weight while walking. Gradually, the baby develops the ability to balance their body, maintain a specific position, and walk independently, minimizing the risk of falling.

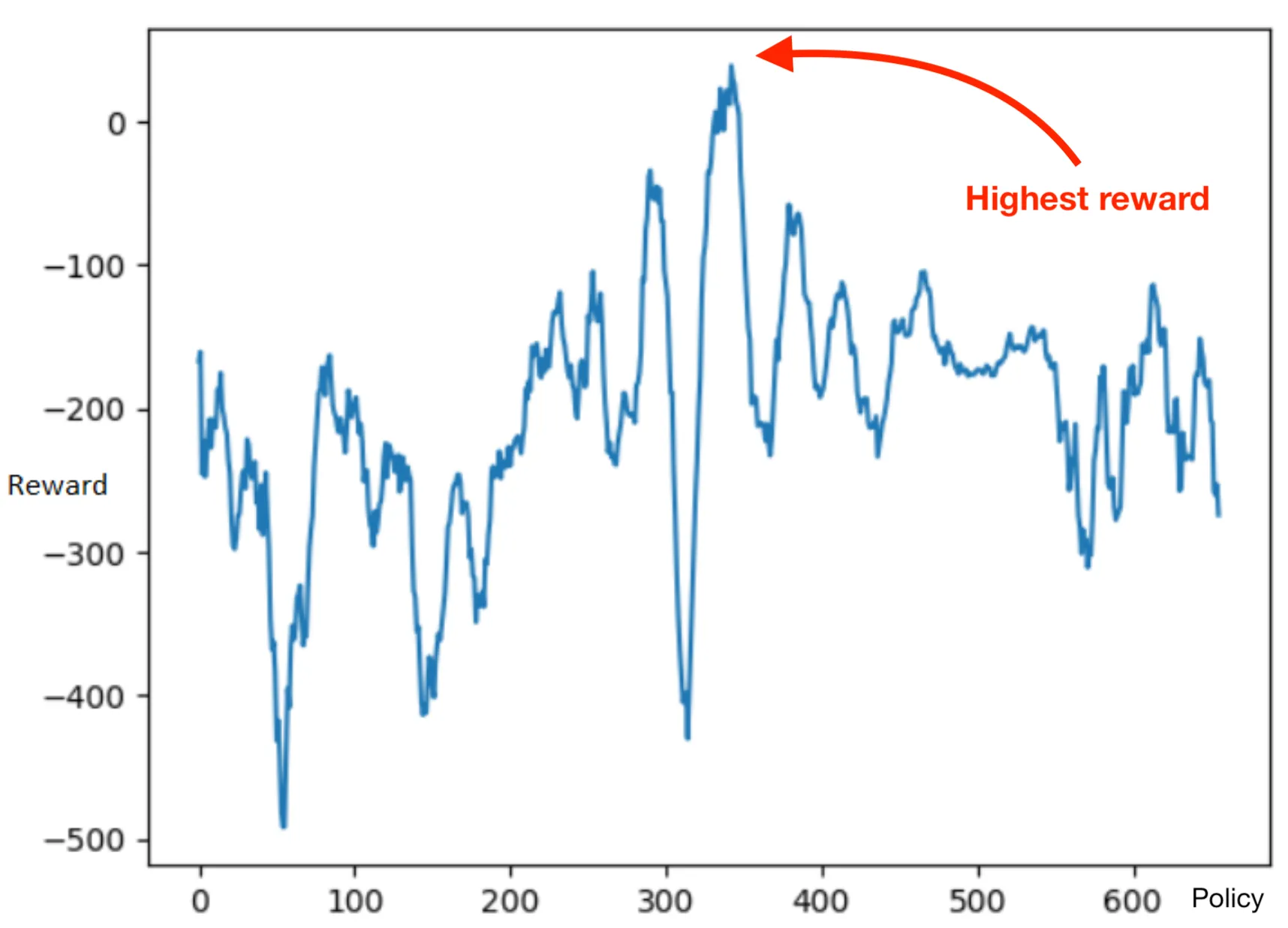
In the same way, Reinforcement Learning enables the model to optimize its "Policies"—or how it behaves—to maximize rewards. As we train the model over time, it identifies the policy that yields the highest reward.
For example, if you’re solving an equation like , there’re different ways to actually solve this, but one of them is shorter and offer a higher reward than the other ways.
Reinforcement Learning isn't a novel concept. It's the driving force behind how robots learn to walk and how Tesla self-driving cars navigate through city streets!
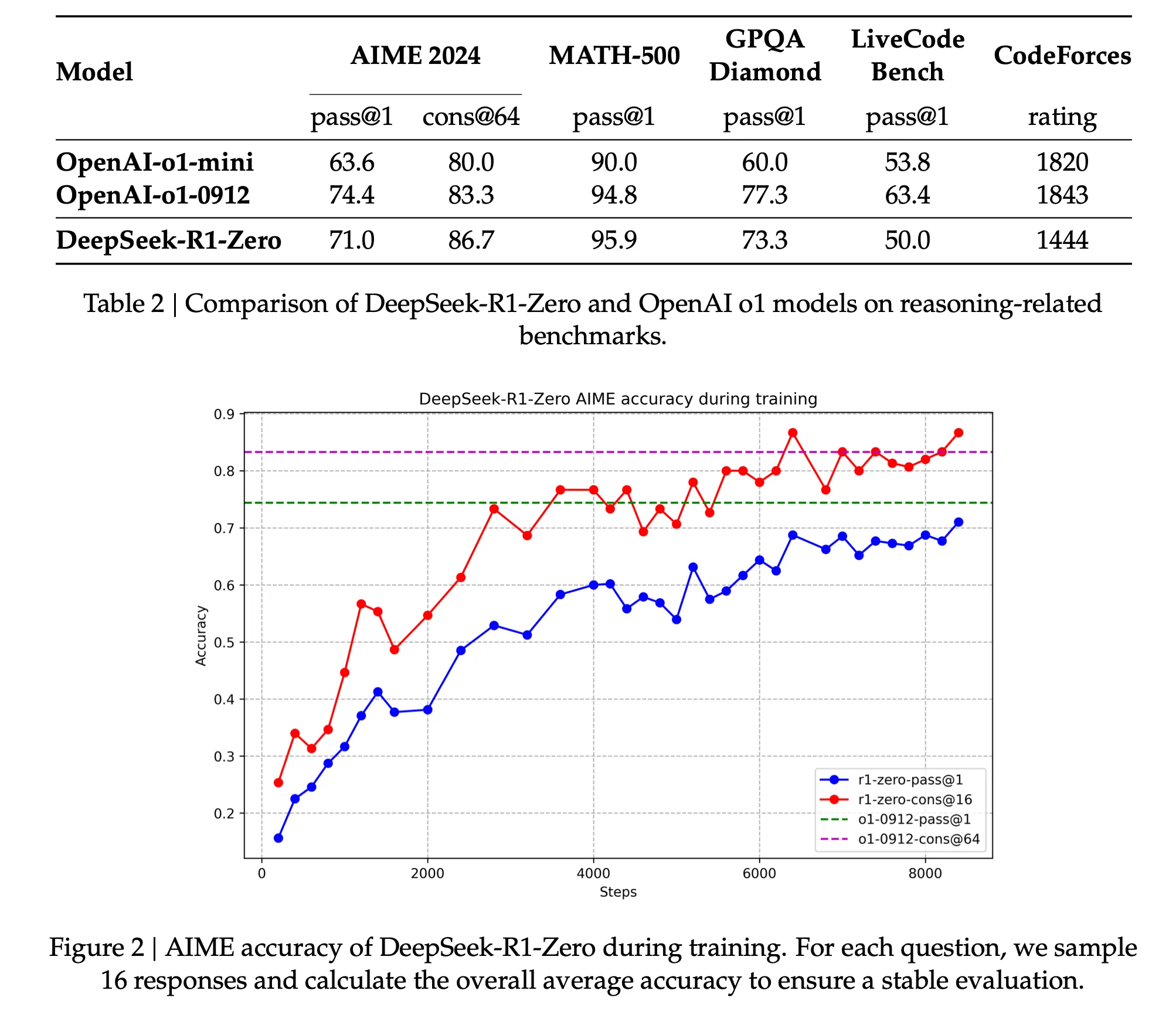
If we analyze this graph from the paper, we can see how DeepSeek R1 improves its question-answering accuracy over time through Reinforcement Learning. By using Chain of Thought reasoning, it improves its responses while we monitor its accuracy rather than simply just providing it with a predefined set of questions and their corresponding answers. More notably, while OpenAI's o1 model maintains a static accuracy, DeepSeek R1 gradually surpasses it. And if the DeepSeek model is trained long enough, we can potentially achieve even greater accuracy rate!
In Reinforcement Learning, we can’t directly tell the model to modify its policy. So that’s why we use Chain of Thought reasoning for the model to self-reflect and to guide its behavior towards achieving the highest possible reward. Unlike explicitly teaching the model how to solve a problem, we provide the model with the right incentives, leading to an improvement in the accuracy of its responses as it re-evaluates its actions.

Group Relative Policy Optimization
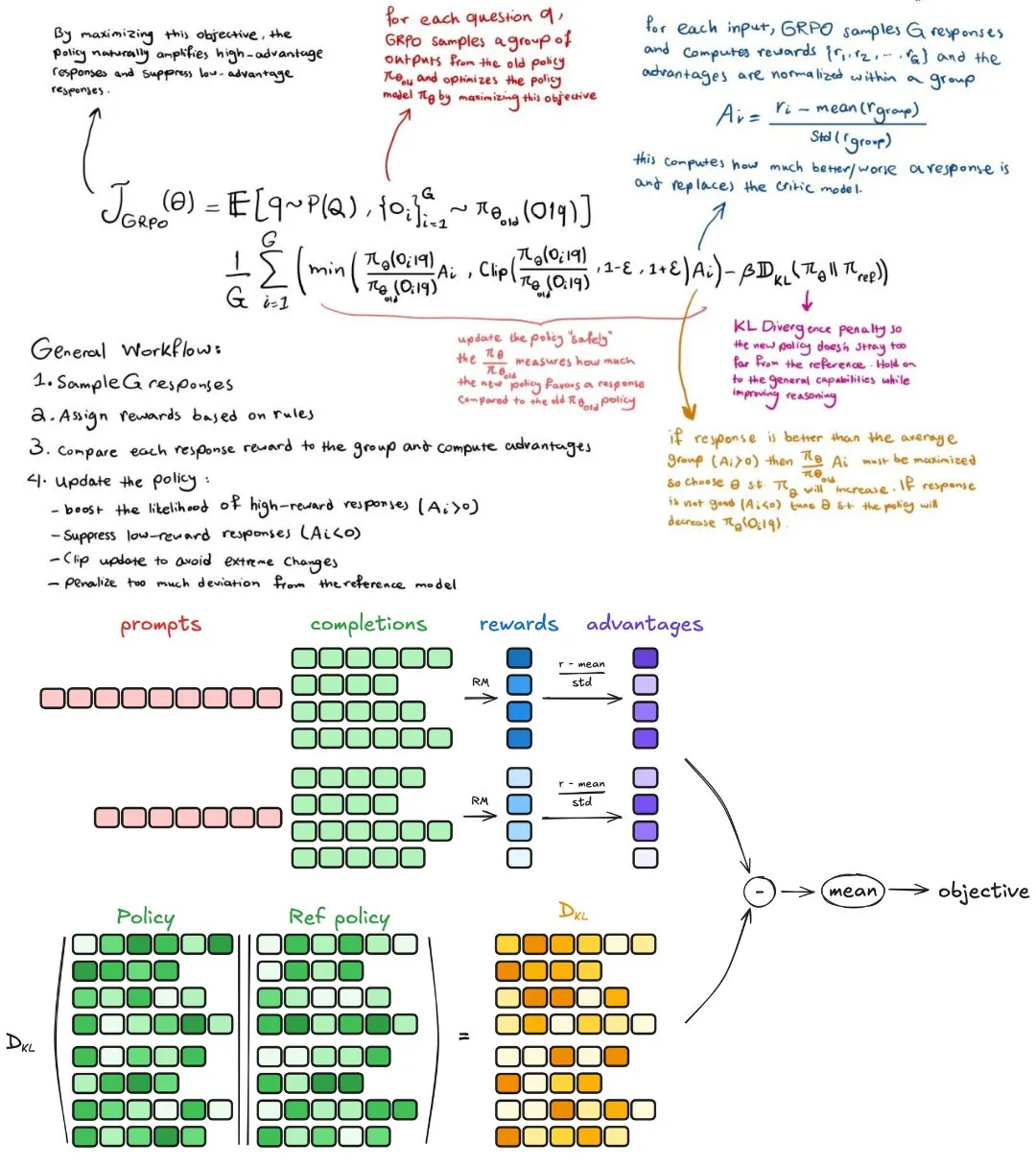
The Group Relative Policy Optimization (GRPO) algorithm is the magic behind DeepSeek R1’s Reinforcement Learning capabilities. It can be presented in this equation:
with and .
The DeepSeek R1 model essentially use this equation to assess the quality of its responses without having the correct answer. Remember, we’re trying to optimize the . We want to modify the so that DeepSeek produces better outputs and generates more accurate answers!
- : Represents the process of sampling each questions and responses to evaluate and optimize the policy.
- : Compare the model's responses with its old policy versus the answers provided by the model's new policy.
- : Restricts how much the policy can change by a factor of and , as we don't want the policy to change excessively, as it could lead to the model's instability.
- : Standardization value measures how well a new policy increases the reward compared to the average reward, in other words, how better or worse the response is.
- If (better than average response) then must be maximized so we need to choose so that the policy is reinforced to increase the likelihood of this response.
- If (worse than average response) so we need to adjust so that the policy is discouraged to decrease the probability of choosing such responses in the future.
- : KL Divergence, a regularization term which ensures that the policy doesn't change too excessive.
In short: We want to change the policy in a “safe” way by comparing the old answers with the new answers so that the reward can be maximized by the policy changes.
I’ve embedded a great diagram of how the GRPO works here:

Model Distillation

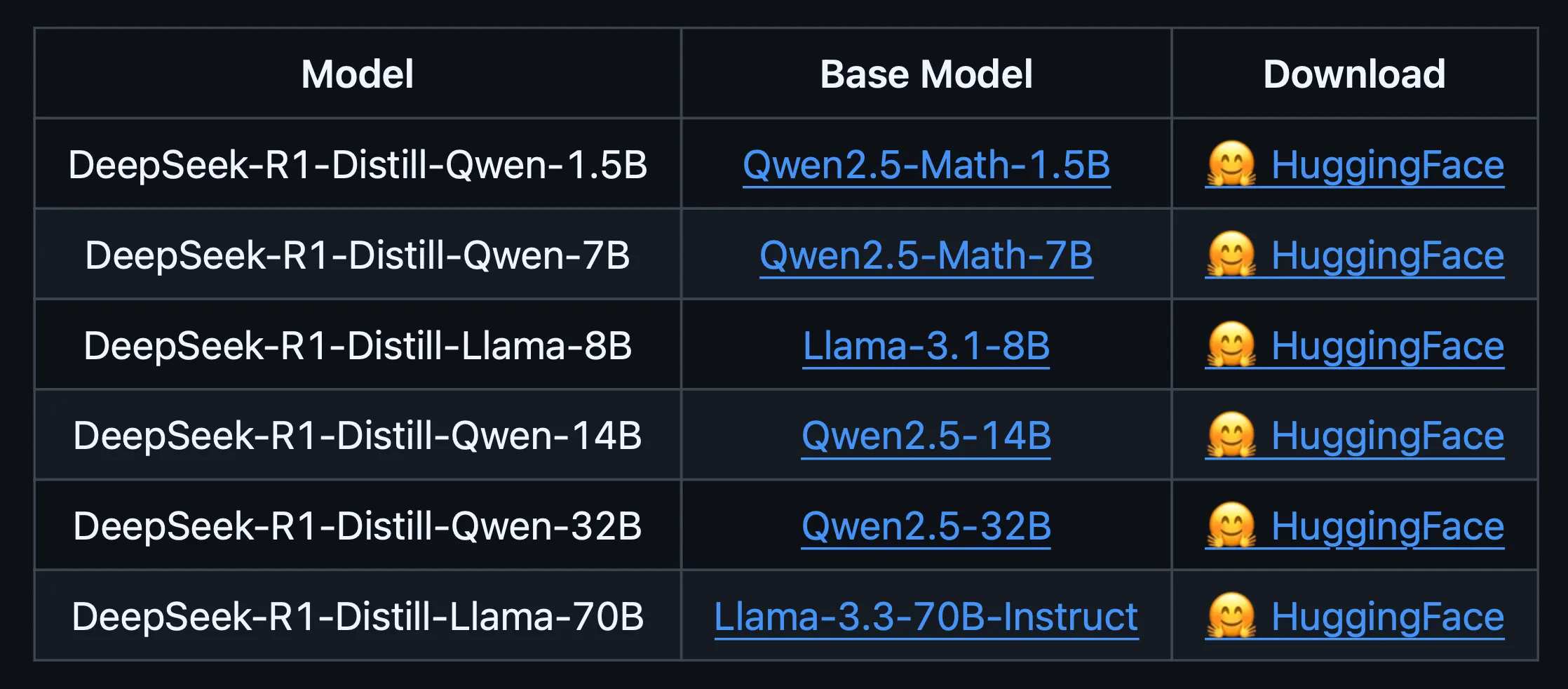
The concept of Model Distillation revolves around the fact that the DeepSeek R1 model has a whopping 671 billion parameters. You’ll need a substantial number of GPUs and an extremely expensive computer to run this model. So to make the model more accessible, they use the larger LLM to train the smaller LLM in Chain of Thought reasoning. This approach enables the smaller LLM to achieve the same level of reasoning and question-answering capabilities as the larger model, albeit with a significantly reduced parameter count.

In their research paper, the researchers distilled their DeepSeek model into smaller models such as Qwen and Llama. Through Chain of Though reasoning, the larger LLM generates numerous examples of its reasoning processes and directly feeds these examples to the smaller LLM. The goal is for the smaller LLM to provide accurate answers to questions similar to those generated by the larger model. This method makes LLMs more accessible to individuals who lack the computational resources to run the full model.
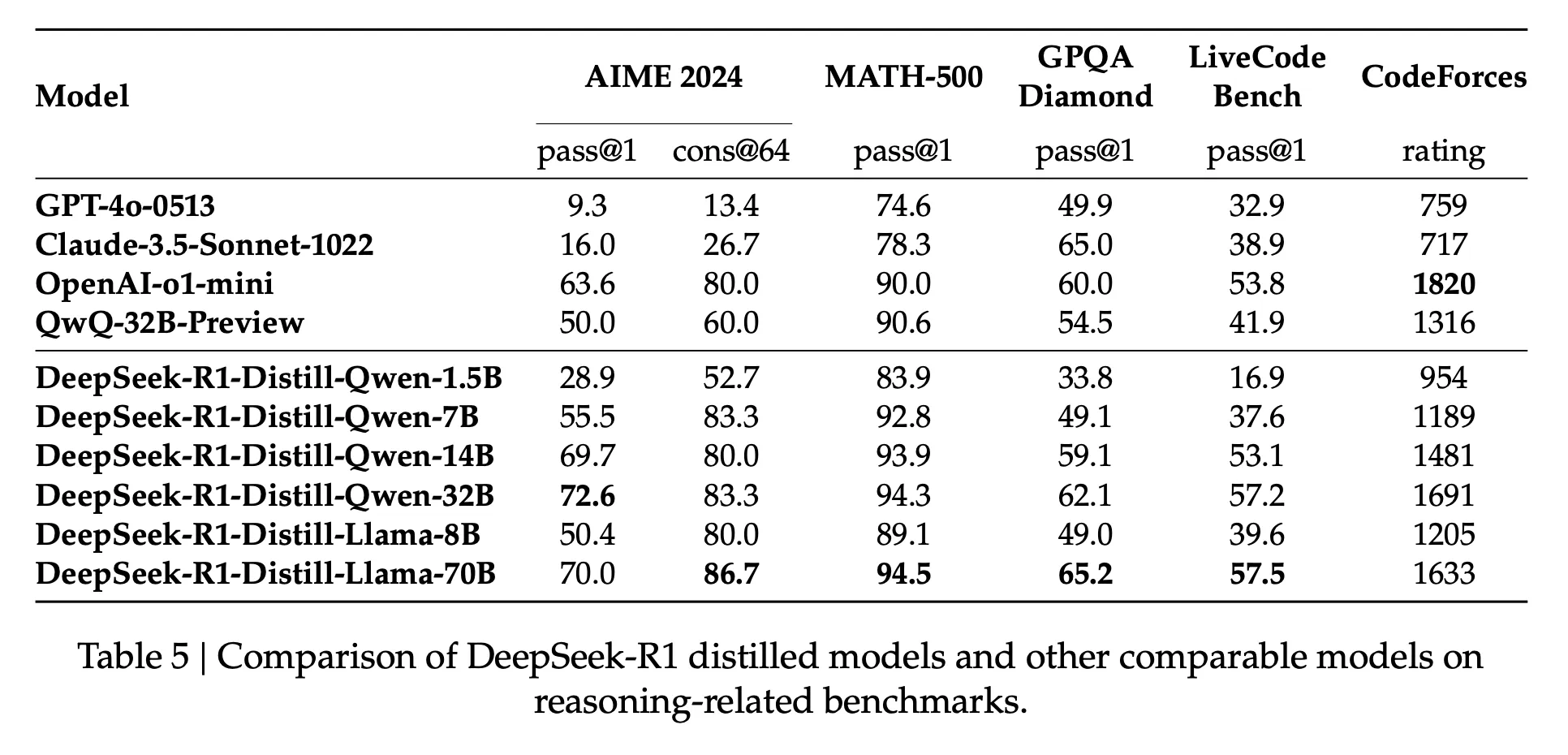
In the research paper, the researchers discovered that during Reinforcement Learning, smaller models actually outperform the larger models by a slight margin. Moreover, this performance comes at a significantly reduced cost in terms of memory and storage requirements. As evident from the provided table, the smaller DeepSeek models outperform other prominent large models like GPT 4o, Claude 3.5 Sonnet, and o1 mini in all the benchmark tests!

Wrapping up
Through the DeepSeek R1 paper, we’ve discovered three new concepts:
- Chain of Thought: This prompting technique guides the model to reason and provide a step-by-step explanation of its thought process.
- Reinforcement Learning: This approach enables the model to make decisions that optimize its "Policies"—or how it behaves—to maximize rewards as it trains over time.
- Model Distillation: The output from DeepSeek R1 is utilized to train smaller models with minimal computational overhead.
👏 Thanks for reading!